Byłem w piątek na odbywającej się na WNSie konferencji Inteligentni, inteligentni i mówiłem o generowaniu tekstów naukowych. A dokładniej, co zrobić, aby generator dawał tekst który ma jakąkolwiek wartość merytoryczną (przede wszystkim ma sens). Bo są przecież generatory takie jak SciGen, czy SnarXiv, które generują mądrze wyglądający tekst, jednak zwykle na pierwszym wrażeniu się kończy — tekst gramatycznie i stylistycznie ma sens, ale semantycznie jest bełkotem (lub co najmniej sprzeczny z rzeczywistością).
Generatory takie są zwykle oparte na gramatyce bezkontekstowej (podobnie zresztą jak niektóre z moich generatorów poezji) — po angielsku context free grammar, CFG — która gwarantuje poprawność gramatyczną tekstu (przynajmniej na gruncie języka angielskiego, który praktycznie nie ma fleksji), ale zarazem z wysokim prawdopodobieństwem gwarantuje, że logiczna struktura tekstu będzie wewnętrznie sprzeczna (o ile użyte będą w nim jakieś anafory, w szczególności wyrażane zaimkami).
Stąd wpadłem na pomysł, aby jako podstawy do generowania tekstów użyć tez KRP (klasycznego rachunku predykatów) z aksjomatyką Peano. Tezy takie (oparte na tautologiach KRZ) można generować, są one oczywiście zawsze prawdziwe (o ile wywodzi się je poprawnie z aksjomatów KRZ i KRP stosując właściwie reguły inferencyjne). Trzeba je natomiast później przekształcić z reprezentacji, jaką nadaje się im w pamięci komputera na reprezentację w języku naturalnym.
Synteza tekstu z formuł logicznych/matematycznych
I tutaj zahaczamy o zagadnienie syntezy języka naturalnego. Istotne jest bowiem, żeby anafory wyrażać raczej w formie zaimków, niż w formie powtórzonych wyrażeń typu „liczba x”. Jest to o tyle istotne, że bez tego tracimy to, co tak istotne było dla generatorów opartych o CFG — stylistyczne wrażenie naukowości tekstu. Patrząc bowiem na tekst naukowy z perspektywy neuroestetycznej możemy dojść do wniosku, że powinien on:
- opisywać problem na tyle skomplikowany, aby tylko naukowcy go zrozumieli (bo zbyt prosty artykuł może nie zostać przyjęty do publikacji w czasopismach naukowych),
- a zarazem na tyle prosty, aby wciąż był zrozumiały dla człowieka (czyli dowody na 40 stron A4 lepiej podawać w formie opisu procedury dowodzenia automatycznego niż explicite, co ja postuluję mówiąc o generatorach),
- wykorzystywać środki stylistyczne wywołujące wrażenie, że tekst pisał inteligentny człowiek, np. zaimki pokazujące, że ma na tyle sprawny umysł (na tyle pojemną pamięć roboczą), że w kolejnych zdaniach wciąż pamięta do czego odnoszą się zaimki będące anaforą dla obiektu/pojęcia wprowadzonego gdzieś wcześniej,
- powinien wywoływać wrażenie poprawnego metodologicznie, które upraszczająco sprowadzam do użycia statystyki i/lub dowodów matematycznych,
Stąd przekładając formułę matematyczną na tekst w języku naturalnym po wstępnym ustaleniu podstawień zwrotów typu „liczba x” pod odpowiednie elementy formuły powinniśmy wykryć anafory i odpowiednio zastąpić je zaimkami. Warto również stosować do opisu niektórych podformuł (tam gdzie da się to zrobić) wyrażenia rzeczownikowe języka naturalnego, które desygnują daną zmienną (wspomnianą „liczbę x”) dodając do niej epitety wyrażające relacje, w jakich się ona znajduje. W ten sposób możemy nawet pominąć samą nazwę zmiennej i zaimek na nią wskazujący i skleić dwa wyrażenia w jedno dłuższe zdanie. Na przykład:
S(…) — następnik …
y — liczba
S(y) — następnik pewnej liczby
x = S(y) — liczba będąca następnikiem pewnej liczby
0 — zero
≠ — jest różne od
x ≠ 0 — x jest różne od zera
Oczywiście tworzone teksty nie muszą być tak proste, jak to, co można powiedzieć o zbiorze liczb naturalnych opisanym arytmetyką Peano. Raz że można podobną operację przeprowadzić na innych zestawach aksjomatów, niż w niżej opisanym eksperymencie, a dwa, że opis może odnosić się do dowolnego obiektu matematycznego izomorficznego ze zbiorem liczb naturalnych (np. do zbioru alefów indeksowanych liczbami naturalnymi). Matematycznie niewiele to wnosi do struktury samego wygenerowanego problemu, ale poszerza spektrum możliwych do wygenerowania z jednej formuły tekstów, co w sytuacji gdy wartością jest dla nas generatywność tekstu, a nie odkrywczość dowodzonych twierdzeń, jest bardzo fajną cechą.
Można również przeprowadzić podobne przełożenie na język naturalny na danych uzyskanych w inny sposób. Szczególnie obiecujące jest tutaj wykorzystanie automatycznej analizy statystycznej wcześniej zgromadzonych danych. W ten sposób badacz co prawda jest potrzebny, do wykonania fizycznej części badania, ale ostatecznie z suchych liczb tekst pracy wygenerować może komputer. Ja jednak w moich eksperymentach ograniczam się na razie do automatycznego wywodzenia tez KRP.
Automatyczne wywodzenie tez KRP
Założyłem sobie, że interesujące są takie tezy, które są krótkie, ale mają długi najkrótszy dowód. Chciałem w tym celu wykorzystać automatyczne wywodzenie tez KRP z aksjomatów KRZ (KRZ bo w modelu KRP znanym mi z logiki aksjomaty KRP powstają z podstawień tautologii KRP). No, z pominięciem kwantyfikatorów, bo doszedłem do wniosku, że niewiele wnoszą, skoro i tak interesują mnie tylko tezy, które mają kwantyfikator na początku, a kwantyfikator wolno mi dostawić na początku każdej tezy:
- Zakładamy, że mamy wywiedzione A.
- Podstawienie aksjomatu KRZ p → p daje aksjomat KRP A → A.
- Reguła dołączenia ∀: A → ∀xA
- Skoro mamy A możemy odrzucić poprzednik implikacji.
- Dostajemy ∀xA q.e.d.
- Zakładamy, że mamy wywiedzione A.
- Podstawienie aksjomatu KRZ p → p daje a. KRP ∃xA → ∃xA.
- Reguła odrzucenia ∃: A → ∃xA
- Skoro mamy A możemy odrzucić poprzednik implikacji.
- Dostajemy ∃xA q.e.d.
Z egzystencjalnym możliwe są jeszcze przypadki dowodzenia, że skoro mamy konkretne podstawienie indywiduów za zmienne, to istnieje takie x, że… etc., ale to też nie wnosi zbyt wiele do tego co mówi sama formuła zawierająca indywidua.
Przeszukując internet w poszukiwaniu wcześniejszych eksperymentów odnośnie automatycznego wywodzenia tez trafiłem na pracę Kazimira Majorinca „Automated Theorem Finding in Propositional Calculus” (czyli mówiąc po polsku „Automatyczne znajdowanie twierdzeń KRZ”).
W znanym mi z logiki modelu KRZ występują dwie reguły inferencyjne — reguła podstawienia i reguła odrywania. Majorinc łączy je w jedną regułę polegającą na dopasowaniu poprzednika implikacji pierwszej formuły, do całości drugiej formuły, tak by dało się zastosować regułę odrywania, a jeśli się to uda — oderwaniu następnika implikacji (z wszystkimi powstałymi podczas dopasowywania podstawieniami). Co istotne dla każdej pary formuł KRZ może istnieć co najwyżej jedno takie podstawienie, nie będące podstawieniem formuły powstałej z innego poprawnego w danym przypadku podstawienia. Mówiąc innymi słowy wszystkie możliwe podstawienia dające możliwość oderwania są pewnymi podstawieniami najogólniejszego podstawienia powstałego poprzez dopasowanie formuł.
W ten sposób wyszukiwanie wszystkich tez sprowadza się do przeszukiwania przestrzeni par formuł będących tezami. Wymaga to oczywiście znajomości elementów ciągu, który generujemy, ale jeśli założymy, że początkowymi elementami są aksjomaty, a nowowywiedzione tezy doklejamy na końcu wygenerowanego już ciągu tez, to możemy przejść przez przestrzeń par tez w taki sposób, że nie ma ryzyka, że będzie nam potrzebna teza, której jeszcze nie wygenerowaliśmy.
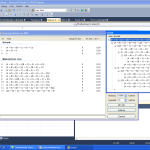
Majorinc chodzi po przestrzeni par wykorzystując numerację Cantora (K. Majorinc „Cantor's Enumerations”). Poniżej wklejam obrazek z podlinkowanego w poprzednim zdaniu bloga Majorinca obrazujący na czym ona polega:

Ja pokusiłem się o trochę więcej eksperymentów z chodzeniem po przestrzeni tez. Najpierw zastosowałem odmienne podejście polegające na rozpoczęciu od tezy (0, 0) (bo numerowałem od zera) i kolejno przeszukiwaniu jednego wiersza i jednej kolumny kolejnych par (w jednym przebiegu pętli, czyli sprawdzam każdą parę normalnie i z odwróconą kolejnością elementów). W ten sposób mam gwarancję, że gdy dojdę do np. tez o dowodzie długości 4, to wszystkie tezy o dowodzie długości 3 mam już wyprowadzone.
Eksperymentowałem też z numeracją Cantora i losowym wybieraniem tez spośród już znalezionych. Trzeba jednak powiedzieć, że z formalnego punktu widzenia moje eksperymenty były dosyć chaotyczne — szukałem bowiem nie tyla algorytmu który znajdzie najlepsze tezy, co algorytmu który znajdzie najciekawiej wyglądające tezy.
Co dalej?
Doszedłem jednak do wniosku, że było to podejście pod kilkoma względami nietrafione. Dlatego algorytm zamierzam zaimplementować od nowa z uwzględnieniem następujących obserwacji:
- C# nakłada pewne ograniczenia jeśli chodzi o naprawdę optymalną implementację podstawiania i odrywania formuł. Łańcuchy w C# są dziwne, zachowują się zupełnie inaczej niż C++'owe char*. Będzie prościej i wydajniej, jeśli zaimplementuję to w C++.
- W swojej C#owej implementacji trzymałem tezy na liście w formie łańcuchów znakowych w notacji prefiksowej (np. „A → b = c” zapisywane było jako „:a=bc”). Okazuje się jednak, że utrudnia to operacje odwołujące się np. do następnika implikacji. Muszę odżałować większe zużycie pamięci i zaimplementować to tym razem na drzewach.
- Nie zaimplementowałem jeszcze schematu indukcji. Trzeba go dodać, bo niektóre tezy tylko w ten sposób da się wywieść.
- Muszę przemyśleć, czy rzeczywiście skupiać się na wywodzeniu z aksjomatów, czy jednak wrócić do CFG. Przede wszystkim dlatego, że coś co ma długi dowód prowadzony według reguł inferencyjnych KRZ/KRP jest banalne do dowiedzenia na gruncie samego języka naturalnego (wystarczą tabele analityczne). Dopiero schemat indukcji daje coś więcej. Muszę pomyśleć jak go połączyć z CFG.